
In my previous post I have showed this short code example:
sparkSession.sql("select * from my_website_visits where post_id=317456")
.write.parquet("s3://reports/visits_report")
And I asked what may be the problem with that code, assuming that the input ( my_website_visits ) is very big and that we filter most of it using the ‘where’ clause.
Well the answer is of course, is that that piece of code may result in a large amount of small files.
Why?
Because we are reading a large input, the number of tasks will be quite large. When filtering out most of the data and then writing it, the number of tasks will remain the same, since no shuffling was done. This means that each task will write only a small amount of data, which means small files on the target path.
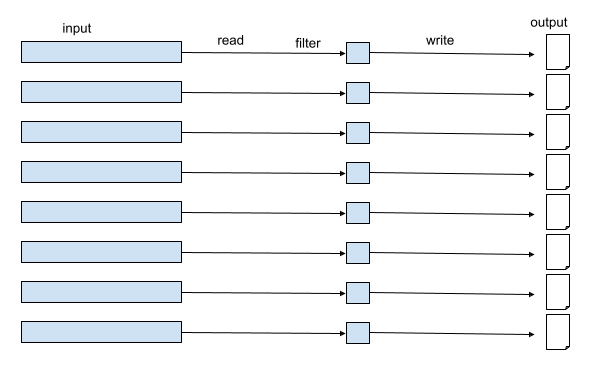
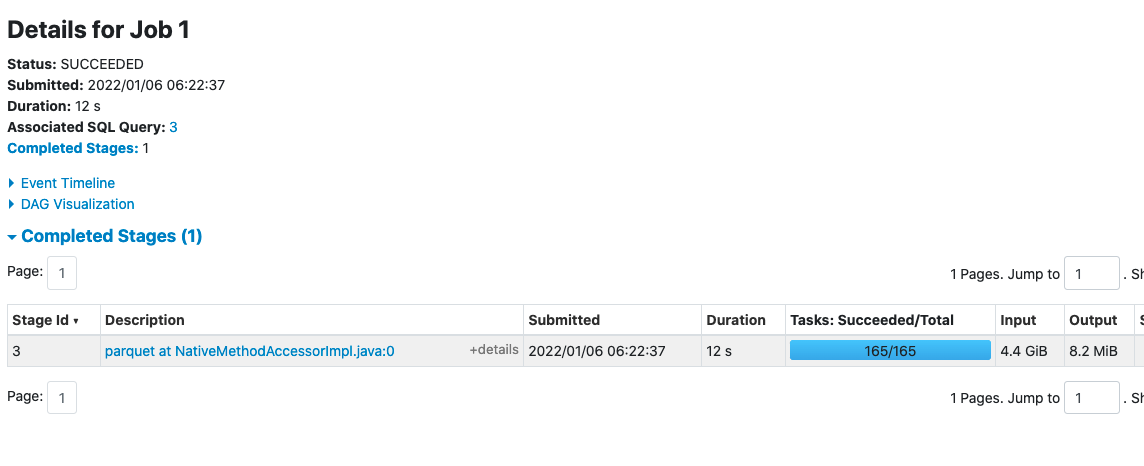
If in the example above Spark created 165 tasks to handle our input. That means that even after filtering most of the data, the output of this process will be at least 165 files with only a few kb in each.
What is the problem with a lot of small files?
Well, first of all, the writing itself is inefficient. More files means unneeded overhead in resources and time. If you’re storing your output on the cloud like AWS S3, this problem may be even worst, since Spark files committer stores files in a temporary location before writing the output to the final location. Only when all the data is done being written to the temporary location, than it is being copied to the final location.
But perhaps worst than the impact a lot of small files have on the writing process, is the impact that they have on the consumers of that data. Since data is usually written once but read multiple times. So when creating the data in multiple small files, you’re also hurting your consumers.
But that’s not all. Sometimes you need to store the output in a partitioned manner. Let’s say that you want to write this data partitioned by country.
sparkSession.sql("select * from my_website_visits where post_id=317456")
.write.partitionBy("country").parquet("s3://reports/visits_report")
That will make things even worst right?
Since now each of those 165 tasks can potentially write a file to each of those partitions. So it can reach up to 165 * (num of countries).
What can be done to solve it?
Well, the obvious solution is of course to use repartition or coalesce. But like I mentioned in my last post make sure to be careful if you’re planning to use coalesce.
If you do partition the data when writing, like we saw above, there is something else that you can do.
sparkSession.sql("select * from my_website_visits where post_id=317456")
.partition("country", 1).write.partitionBy("country").parquet("s3://reports/visits_report")
In the example above we partitioned the data by country even before writing. Therefore I am expecting to have only 1 file per country.