Finding data on the data lake can sometimes be a challenge. At my current workplace (ZipRecruiter) we have hundreds of tables on the data lake and it’s growing each day. We store the data on AWS S3 and we use AWS Glue Catalog as meta data for our Hive tables.
But even with Glue Catalog, finding data on the data lake can still be a hustle. Let’s say I am trying to find a certain type of data, like ‘clicks’ for example. It would be very nice to have an easy way to get all the clicks related tables (including aggregation tables, join tables and so on..) so i could choose from. Or perhaps I would like to know which tables were generated by a specific application. There is no easy way to find these table by default.
But here is something pretty cool that I recently found about Glue Catalog that can help.
If you add properties to glue tables, then you can search tables based on those properties.
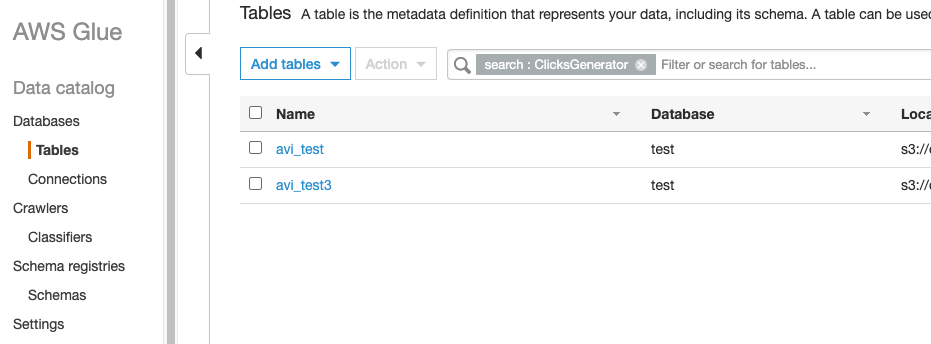
For example, if you would add the property “clicks” to all the job related tables, then you can get all of those tables as a result by searching the phrase “clicks” in GlueCatalog.
You can also add property like “Application: ClicksGenerator” to all of the tables that were generated by the ClicksGenerator application.
Other ideas for labels may be: team names, last update date, data lag, data update frequency, and so on…