Working with AWS EMR has a lot of benefits. But when it comes to metrics, AWS currently does not supply a proper solution for collecting cluster metrics from EMRs.
Well, there is AWS Cloudwatch of course, which works out of the box and gives you loads of EMR metrics. The problem with CloudWatch is that it doesn’t give you the ability to follow metrics per a business unit, or a tag, only per a specific EMR id. This simply means you can not compare the metrics over time, only for specific EMRs.
Let me explain again the problem. A common use of EMR, is that you write some kind of code that will be executed inside an EMR, and will be triggered every given amount of time, lets say every 5 hours.
This means that every 5 hours a new EMR, with a new ID will be spawned. In CloudWatch you can see each of these EMRs individually but not in a single graph, which is defiantly a disadvantage.
Just to note, I am referring only to machine metrics, like memory, cpu and disk. Other metrics like jvm metrics or business metrics, are usually collected by the process itself and obviously can be collected easily over time per business unit.
Another problem is that some of these metrics demand extra cost so they would be collected and displayed by Cloudwatch.
I found a nice and easy solution for this problem. I wrote a small script which collects metrics from the machine it is executed on, for every given amount of time, and sends those metrics to a Graphite host. This script should be added to the EMR as a bootstrap action. In this way, all of the cluster machines will send their metrics to Graphite. Since the script would use the same namespace all the time, the outcome graph will show you not only the metrics for the current execution, but also for the history of previous executions.
BTW, I used Graphite since this is what we prefer over at my job, but the same solution could easily used other APIs instead, like AWS CloudWatch API for example.
export GRAPHITE_HOST="metrics.mydomain.com"
export GRAPHITE_PORT=2003
export TIER=$(aws emr describe-cluster --cluster-id $(sudo cat /mnt/var/lib/info/job-flow.json | jq -r ".jobFlowId") --query Cluster.Tags | jq -r -c '.[] | select(.Key | contains("Tier"))? | .Value' | tr '[:upper:]' '[:lower:]') || exit 1
export IS_MASTER=$(cat /mnt/var/lib/info/instance.json | jq -r ".isMaster") || exit 1
if [[ $IS_MASTER == "true" ]]; then
export namespace_prefix="master"
else
export namespace_prefix="nodes"
fi
send_loop()
{
while :
do
echo "${1}.${namespace_prefix}_free_memory `free -m | awk -v RS="" '{print $10 "+" $17 "+" $21}' | bc` `date +%s`" | nc ${GRAPHITE_HOST} ${GRAPHITE_PORT}
echo "${1}.${namespace_prefix}_cpu_utilization `top -b -n1 | grep "Cpu(s)" | awk '{print $2 + $4}' | bc` `date +%s`" | nc ${GRAPHITE_HOST} ${GRAPHITE_PORT}
echo "${1}.${namespace_prefix}_free_disk `df --output=avail / | grep -v Avail | bc` `date +%s`" | nc ${GRAPHITE_HOST} ${GRAPHITE_PORT}
sleep ${2}
done
}
send_loop $1 $2 &
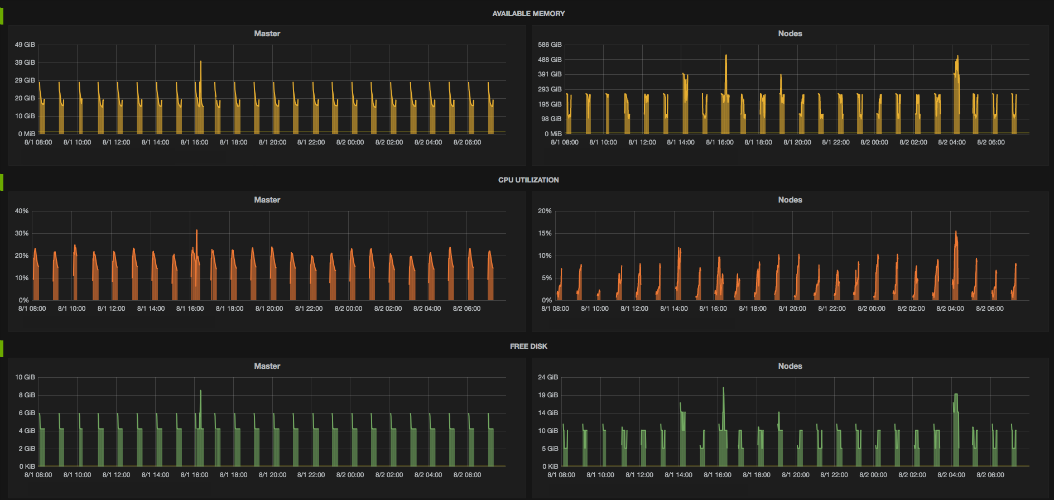
This script currently sends 3 types of metrics: available memory, cpu usage and free disk space.
Those metrics are actually aggregated separately for the master node and worker nodes. So in fact we have here 6 metrics.
This script has 2 parameters:
1. A namespace prefix. This namespace prefix will be attached with each of the 3 metrics and for master and workers nodes.
so in case the namespace is a.b, the metrics that will be sent will be:
a.b.master_free_memory
a.b.master_cpu_utilization
a.b.master_free_disk
a.b.nodes_free_memory
a.b.nodes_cpu_utilization
a.b.nodes_free_disk
2. The frequency in seconds that the metrics should be collected and sent to Graphite
How to use the script
1. Copy it and set the GRAPHITE_HOST value inside the script.
2. Upload it to S3.
3. Add it as a bootstrap action to your EMRs.
4. Set the 2 input parameters mentioned above.
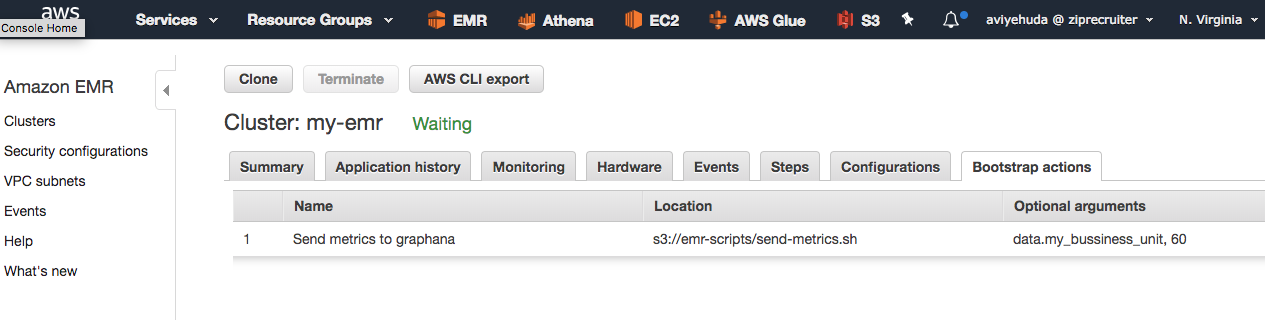
The result